



















なぜ今「質と量のバランス」が重要なのか
AIモデルの性能は、学習に用いるデータの質と量に大きく左右されます。かつては「とにかく大量に集める」ことが重視されていましたが、現在では状況が変わりつつあります。モデルの精度だけでなく、学習コスト、運用効率、倫理的な配慮まで含めたデータ設計が求められるようになってきました。
特に、生成系AIや対話型モデルなど、文脈理解や多様性が重要となる領域では、単純なデータ量の増加が必ずしも精度向上につながらないことがわかっています。AI開発において「どこまで集めれば足りるのか?」という問いは、戦略設計の出発点になりつつあります。
データ量の利点と落とし穴
大量のデータを使うことで、モデルは多様なパターンを学習でき、未知の入力に対する汎化性能が向上する可能性があります。たとえば画像認識モデルでは、照明条件や背景、角度の異なる画像が揃っているほど、実運用時の精度が安定します。
一方で、データ量が増えるほどノイズや重複、ラベルミスといった問題も同じ割合で増加します。これらは学習を妨げ、精度低下の原因になるケースもあります。また、データ収集から前処理、学習に至るまでのコストは膨大で、GPUリソースや学習時間は開発スケジュールや予算に直結します。
「量が多ければ安心」という発想は、現代のAI開発では再考が必要です。
データ量の見極めポイント
「質の高いデータ」とはタスクによって基準が異なります。
分類タスクではラベルの一貫性や正確性が重要となり、画像認識タスクでは照明・アングル・背景など撮影条件や被写体バリエーションの網羅性が問われます。対話モデルでは自然な応答、文脈の整合性、多様な言語スタイルが求められます。
質を判断する主な観点は次の通りです。
- データの多様性(属性、文脈、ジャンルなど)
- バイアスの有無と偏りの程度
- 実運用環境との整合性(ドメイン適合性)
画像認識タスクの場合も同様に、
- 撮影環境(照明、天候、屋内外)
- カメラ機種や解像度
- 画角・アングル・被写体との距離
- 被写体の属性(年齢層・性別・服装・背景との組み合わせ)
などのバリエーションをどれだけ網羅できているかが「質」の一部になります。さらに、人物や特定の建物が写る場合は、権利処理(モデルリリース・プロパティリリース)やプライバシー配慮がなされているかも重要な評価軸です。
たとえば医療チャットボットの開発では、専門用語の正確な使用や患者との対話文脈が含まれているかが重要です。画像タスクであれば、実際の利用シーンに近い条件で撮影されたデータが揃っているかが鍵になります。単なる量ではなく、目的に即した「意味のある質」が問われます。
実務でのバランス戦略
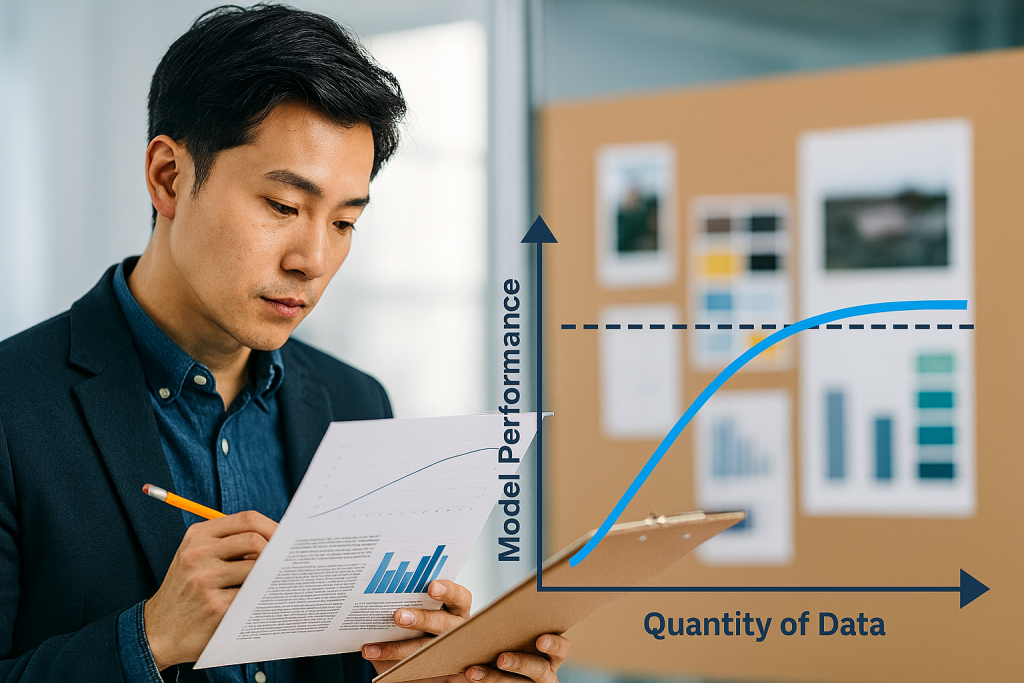
実務では、プロジェクトのフェーズに応じて「質と量のバランス」を柔軟に設計する必要があります。PoC(概念実証)段階では、少量でも高品質なデータで十分な検証ができます。一方、商用展開ではスケーラビリティと多様性を確保するために、一定量のデータが必要になります。
見落とされがちなのが、データ収集・アノテーションにかかる時間とコストです。特に専門領域データの場合、外部委託が多く、以下の要因が納期に影響します。
特にアノテーション付きデータや専門領域の文脈データは外部ベンダーに委託するケースが多く、次のような工程で時間と工数が積み上がっていきます。
- データ仕様の明確化と共有にかかる準備期間
「どの粒度でラベルを付けるか」「NG例は何か」「判断が迷うグレーゾーンはどう扱うか」といったルールを文章化し、ベンダーとすり合わせるだけで数週間かかることもあります。 - アノテーションルールの設計と教育
最初から高品質なラベルはつかないため、テストデータで練習 → フィードバック → 再トライ…を繰り返す必要があり、この間は本番データを思ったほど進められません。 - 品質管理・再修正の往復
納品されたデータをサンプリング確認すると、一定割合で「やり直し」が発生します。結果として、「10万件お願いしたのに、モデル学習にそのまま使えるのは7〜8万件だった」といったギャップが生まれます。 - 法的・倫理的な確認プロセス(個人情報・著作権など)
収集した画像やテキストの中から、権利的に使えないものを除外する工程も必要です。ここで一定数が“NG扱い”になり、件数ベースではさらに目減りします。
こうした要素が積み重なることで、机上の計画として想定した「必要なデータ量」と、実際に 期間内に集めて、かつ学習に使える状態まで持っていける“収集可能な量” とのあいだにはギャップが生まれます。
たとえば「理想は100万件ほしい」と考えても、仕様調整・教育・修正・権利チェックを行った結果、納期内に実用レベルまで仕上がるのは30万件程度、ということは珍しくありません。
だからこそ調達を担う立場としては、モデル開発側と早い段階でコミュニケーションをとり、
- どのタスクにどのデータを優先的に割り当てるか
- まずは小さく始めて、追加収集を前提に段階的に増やすか
といった「収集可能かつ運用可能なデータ設計」を一緒に描くことが重要になります。
バランスを取るための実践的な手法としては…
- フィルタリングや重複排除の自動化
- アノテーション精度のモニタリングと改善
- 既存データの再利用と拡張(データ拡張、合成データの活用)
- モデルのエラー分析を通じたデータ追加の最適化
たとえば、分類モデルで特定のクラスの誤認識が多い場合、そのクラスに特化した追加データを収集することで、効率的に精度を向上させることができます。外注先との連携を含めた「調達設計」こそが、開発全体のスピードと品質を左右する鍵になります。
AIプロジェクトにおけるデータ量設計のステップ
AI開発では、感覚的な判断ではなく、次のステップに沿ってデータ量を設計することが理想的です。
- STEP1目的と精度要件の定義
- 達成したいタスク(分類、生成、検知など)を明確化
- 必要な精度指標(例:誤検知率5%以下、F1スコア0.9以上)を設定
- STEP2小規模データでのPoC(概念実証)
- まずは1,000〜5,000件の高品質データで試作
- 学習曲線から、量を増やすべきか質の改善が必要か判断
- STEP3学習曲線とエラー分析
- データ量と精度の関係を可視化し、伸びが鈍化するポイントを確認
- 誤認識の多いクラスや属性を特定し、追加データの方向性を決定
- STEP4調達可能性と納期の考慮
- 外注と社内収集のリードタイムを見積もり、現実的な収集量を設定
- “理想の量”ではなく“運用可能な量”を定義する
- STEP5反復的な改善
- 精度が頭打ちになったら、質の見直しや合成データの活用を検討
- データ収集とモデル改善を繰り返し、最適点を探る
量の目安は「目的×モデル×制約」で変わる
| タスク例 | 初期目安(参考) | 備考 |
|---|---|---|
| 画像分類(10クラス) | 1万〜5万枚 | クラスごとのバランスが重要 |
| 会話生成(汎用) | 数十万〜数百万文 | 多様性と文脈の深さが鍵 |
| 異常検知(製造) | 正常データ:数万〜数十万件 異常データ:数百〜数千件 | 異常データは少量でも有効 |
データ量は、目的・制約・評価指標・調達可能性の交差点で決まります。調達や設計の担当者が初期から関与することで、無駄な収集や過剰設計を避け、開発全体のROIを高めることができます。
質と量の「ちょうどいい」は目的次第
AI開発で求められる「最適なデータの質と量」は、プロジェクトの目的やフェーズ、予算、運用体制によって変わります。絶対的な正解はありませんが、判断軸を持つことで無駄な収集や過剰な学習を避け、効率的な開発につながります。
「足りるかどうか」はモデルの精度だけでなく、運用可能性、保守性、倫理的妥当性も含めて考える必要があります。データ設計そのものが、AI開発企業の競争力となる時代が来ています。

