



















AI開発を進めるうえで、多くの企業が最初にぶつかるのが「データをどう集めるか」という課題です。
必要なデータ量は膨大で、社内では人手やノウハウが足りず、思うように進まない──。
「アノテーション精度が安定しない」「権利処理が不安」「時間とコストがかかる」といった声も少なくありません。
AIの精度を決めるのはアルゴリズムではなく“データの質”。
本記事では、AIデータ収集を社内で行う場合と外注する場合の違いを比較し、コスト・品質・スピードの観点から最適な方法を探ります。
AIデータ収集における課題とは?
AI開発の現場では、「人手」「品質」「管理」の3つの壁が立ちはだかります。
専任人材がいない、ルールが統一されない、バージョン管理や権利確認が煩雑──。
結果としてデータ整備が遅れ、開発スケジュール全体を圧迫してしまうこともあります。
また、社員が兼任で対応したり、安価なクラウドソーシングを利用した結果、品質が安定せず再作業が発生するケースも少なくありません。
AIプロジェクトの停滞原因の多くは、この“データ収集フェーズ”に潜んでいます。
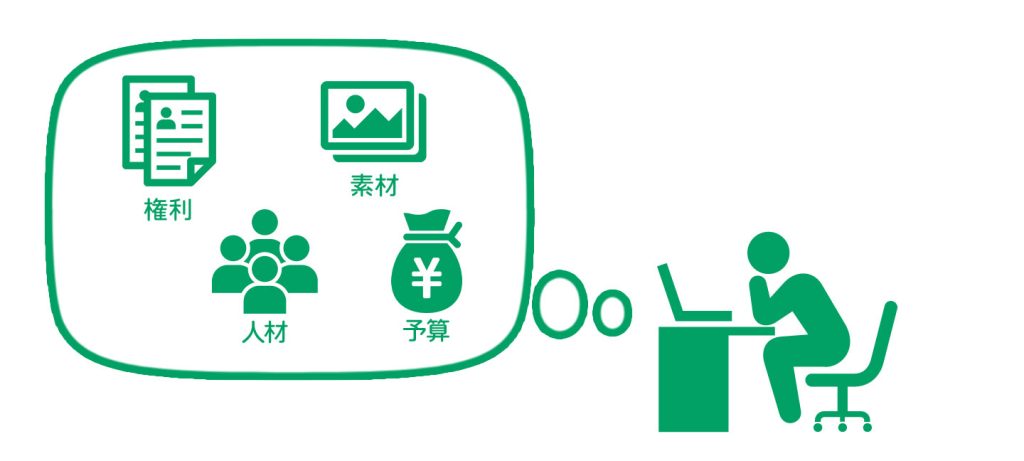
社内対応で起きがちなトラブル例
AIデータ収集は一見単純作業に見えますが、実際には「ルール設計」「品質管理」「権利確認」「再検証」といった複雑な工程が連鎖しています。
そのため、専任体制がないまま進めると、どこかで精度の限界やリソース不足にぶつかりやすいのです。
- 社員が兼任でデータを集めた結果、精度や基準が統一されない
- 外部のクラウドソーシングを安価に使ったが、ラベル精度が低く再作業に
- 著作権や個人情報を考慮せず、データを再収集する羽目に
- 結果として「予定の3倍の時間とコスト」がかかることも
なぜデータ収集でつまずくのか
AIの学習精度は、アルゴリズムそのものよりも「どんなデータで学習したか」に強く左右されます。
にもかかわらず、社内でデータを集めようとすると以下のような課題が積み重なります。
- 仕様変更のたびに収集ルールや命名規則を再定義しなければならない
- ツール整備や環境構築に想定外の時間がかかる
- ラベル精度を担保するためのダブルチェック体制が組めない
- データの偏りや権利リスクが後になって発覚し、全体のスケジュールを圧迫する
結果として、「データ準備が追いつかず、モデル検証に入れない」という状況が起こります。
AI開発プロジェクトの停滞原因の多くは、この“データ収集フェーズ”に潜んでいます。
AIデータ収集は、単なる前工程ではなく、プロジェクト全体の品質とスピードを決定づける基盤です。
次章では、そもそも「AIデータ収集」とは何を指し、どのようなプロセスが含まれるのかを整理していきます。
AIデータ収集の基本プロセスと種類
AIデータ収集とは、AIモデルが学習に使うデータを集め・整理し・整える工程を指します。
目的に応じて画像・音声・テキストなどを収集し、ラベル付けや検証を経て学習に活用します。
AIデータ収集の主な種類
| 画像データ | 写真・イラスト・動画からの静止画など | 物体検出、顔認識、医療画像解析 |
| 音声データ | 音声・環境音・発話データ | 音声認識、感情解析、AIアシスタント |
| テキストデータ | 記事・SNS投稿・チャットログなど | 自然言語処理、要約、感情分析 |
| センサーデータ | IoT機器・自動車・ロボットからのログ | 予知保全、自動運転、行動解析 |
| マルチモーダルデータ | 画像+音声+テキストなどの複合データ | 会話AI、映像理解、生成AI学習 |
これらのデータを単に集めるだけでは不十分で、「正確なラベル付け」や「権利・利用許諾の確認」といった下準備が不可欠です。
データ収集の基本プロセス
- 要件定義
何を目的に、どのような条件のデータを集めるかを明確にする
(例:「日本語で感情を判定する会話音声」など) - 収集
社内リソース・外部API・既存データセット・クラウドソーシングなどを活用してデータを収集 - アノテーション(ラベル付け)
AIが理解できるよう、人の手でタグ・属性・分類情報を付与 - 検証・クリーニング
重複・誤ラベル・品質低下データを排除し、統一フォーマットに整える - 利用・管理
データベースやクラウド上で管理し、学習・検証フェーズに活用
この一連の流れの中で、特に時間とコストがかかるのが「収集」と「アノテーション」です。
外注を検討するきっかけとなる最も大きなポイントでもあります。
データ収集で求められる品質要件
AI開発で利用するデータは、以下の4つの基準を満たすことが理想とされます。
多様性
偏りのないデータ構成
(性別・年齢・環境など)
正確性
ラベルや分類の一貫性・精度
合法性
著作権・個人情報・モデルリリースの明確化
再現性
同条件下で再収集できる明確な仕様設計
これらを満たすためには、単なる「収集作業」ではなく、プロジェクト全体を通じた品質管理体制が不可欠になります。
AIデータの収集は「素材集め」ではなく、AIの精度と安全性を決定づける設計工程です。
そして、時間とコストはこの2工程に集中しています。
次章では、社内でこの工程を行う場合の特徴と、そこで直面するリスクについて具体的に見ていきます。
社内でデータ収集を行う場合の特徴とリスク
まず、AIデータ収集を社内で完結させることによる明確なメリットがいくつかあります。
- 機密性の担保
社内ネットワーク内で完結するため、未公開の研究テーマや顧客情報などを外部に出さずに済みます。
特に医療・製造・金融などの分野では、セキュリティ面の安心感は大きな利点です。 - 自社知見の活用
ドメイン知識を持つ社員がデータの選定や分類を行うことで、目的に沿った精度の高いデータを構築しやすいです。 - 柔軟な対応が可能
仕様変更や追加要件にも即応しやすく、スピード感を保ちやすい傾向がりあります。
外部委託のような発注・契約手続きが不要な点も魅力です。
このように、社内対応の強みは機密性と柔軟性です。
社内完結で情報漏えいリスクを抑え、自社の知見を反映しやすい点は大きな利点。
しかし、リソース不足・ツール未整備・品質のばらつきといった課題を抱えやすく、担当者の属人化やスケジュール遅延につながることもあります。
また、社内コストは可視化しづらく、人件費や再作業時間を含めると結果的に外注より高くつくケースも珍しくありません。
外注・委託でデータ収集を行うメリット
- 専門チームによる高品質なデータ構築
・AI開発経験を持つ人材が担当
・品質基準や検証プロセスが標準化
・再ラベル、検証対応まで一貫処理 - 法務・セキュリティ面での安心感
・ISMSやPマーク取得など管理体制が整備済み
・モデルリリース・著作権処理の代行が可能
・NDA(秘密保持契約)締結で安全な取引
- コストとスピードの最適化
・固定費が不要で、必要な分だけ発注可能
・教育、ツール整備などの初期コストが不要
・納期と作業量の見通しが立てやすい - 開発チームの負担軽減と集中化
・社内リソースをコア業務(設計・分析)に集中
・データ整備の専門工程を外部化
・プロジェクト全体のスピードアップ
外注は単なる作業代行ではなく、品質・スピード・コスト・リスク管理を最適化する手段です。
社内の限られた人員では難しい部分を補い、AI開発をより確実かつ効率的に進めることができます。
外注するときの注意点と失敗しないためのポイント

コミュニケーション不足によるズレ
外注でよくあるトラブルの一つが、要件のすり合わせ不足による品質のばらつきです。
「何を」「どのレベルまで」「どんな基準で」集めるのかを明確にしないまま依頼すると、期待していたデータ形式と異なったり、再作業が発生したりするリスクがあります。
- データサンプルや出力例を提示して、完成イメージを共有する
- ラベル基準書・チェックリストを事前に作成する
- 小ロットでの試験発注(PoC)を行い、品質を確認してから本契約に進む
最初の要件定義を丁寧に行うことが、トラブル回避の第一歩です。
品質管理体制の確認不足
外注先によっては、検品・再確認体制が不十分なまま大量データを納品するケースもあります。
そのため、単に「納品実績が多い」だけでなく、品質保証プロセスが明文化されているかを必ず確認しましょう。
- 二重チェック体制(アノテーター+検証者)があるか
- ラベルガイドラインやエラー分類ルールを運用しているか
- 品質検証レポート(正答率・再現率など)を提出してもらえるか
品質に対する姿勢が不明確な外注先は、長期的なパートナーとしてリスクが高いといえます。
セキュリティ・法務面のリスク管理
AIデータには、個人情報や著作権のある素材が含まれることも多いため、セキュリティや権利処理に関する契約内容は特に注意が必要です。
- NDA(秘密保持契約)や個人情報保護契約の締結
- モデルリリース・プロパティリリースの取得方針
- データの保存・削除ポリシー
- 外注先がISMS・Pマークなどを取得しているか
これらを明確にしておくことで、納品後のトラブル防止と法的リスク低減につながります。
コストと納期のバランスに注意
安さやスピードだけで外注先を選ぶと、品質が犠牲になるケースがあります。
AI開発においては、「精度を高めるデータ」に価値があるため、単価よりも成果物の品質基準と検証体制を重視すべきです。
また、納期設定も現実的であるかを見極めましょう。
極端な短納期は作業負担を増やし、ラベル精度の低下や作業者の疲弊につながり、結果的に自分の首を絞めることになります。
依頼前に確認しておきたい要件整理についてはこちらの記事をどうぞ

外注を成功させるカギは、「丸投げしないこと」です。
要件・品質・契約・セキュリティを丁寧に整理し、パートナーとして信頼できる相手を選ぶことが何より重要です。
【比較表】社内対応 vs 外注の違いを比較

AIデータ収集は、どのフェーズに重点を置くかによって「社内対応」と「外注対応」で最適解が変わります。
ここでは、主要な5つの観点で両者を比較してみましょう。
社内対応と外注対応の違い
| 項目 | 社内対応 | 外注対応 |
|---|---|---|
| コスト構造 | 人件費・教育費・ツール費など固定費が多い。 短期的には安く見えるが、長期化すると増大しやすい。 | 作業量に応じた変動費。明確な見積もりが出せ、 必要なときに必要な分だけ発注できる。 |
| 品質 | 社内ノウハウ次第でばらつきあり。 専任体制がないとラベル精度が不安定になりやすい。 | 専門チームによる品質管理体制。 検証などのプロセスが標準化されている。 |
| スピード | 限られた人員で対応するため、 スケジュール調整に時間がかかる。 | 大規模体制で短納期にも対応可能。 タスクを分散処理できる。 |
| セキュリティ・権利処理 | 自社環境内で完結するため情報管理はしやすいが、 リリース・著作権処理は社内負担。 | NDAやリリース処理を外注先が代行可能。 ISMS・Pマークなど体制を持つ企業も多い。 |
| 柔軟性 | 仕様変更や緊急対応がしやすい。 社内判断で即時対応可能。 | 契約単位での変更が必要な場合も。 初期段階で要件を明確にしておくことが前提。 |
比較すると、社内対応は柔軟性と機密性に優れ、外注対応はスピードと品質管理に強いことがわかります。
社内対応は小規模や試験的な開発に適し、外注は大量データや高精度を求める本格開発に向いています。
コスト・リスク・リソースのバランスを見極め、目的と体制に応じて最適な方法を選ぶことが重要です。
近年では、要件定義を社内で行い、収集やアノテーションを外注するハイブリッド型も増えています。
ハイブリッド運用という選択肢
最近では、「社内+外注」を組み合わせたハイブリッド型の運用を採用する企業も増えています。
たとえば次のような分担です:
- 要件定義・品質検証 → 社内
- データ収集・アノテーション → 外注
これにより、社内の知見を活かしつつ、外部の作業力でスピードと品質を両立できます。
特にAI開発の初期段階や、継続的な学習データ更新を行うプロジェクトでは効果的です。
「社内対応」と「外注対応」には、それぞれ明確な強みがあります。
重要なのは、目的・データ量・リスク許容度・納期などの条件に応じて、最適な方法を選ぶことです。
外注先を選ぶときのチェックポイント
外注先を選ぶ際は、実績・品質・セキュリティ・対応力の4軸で確認します。
まず、自社と近い分野や規模の実績があるか。
次に、品質基準・二重チェック体制などの仕組みが整っているか。
さらに、ISMS・Pマーク取得やNDA締結など法務体制の有無も重要です。
専任担当がつき、進行中の修正や要件変更に柔軟に対応できるかも確認しましょう。
最適なデータ収集方法を選ぶために
AI開発の精度とスピードを決めるのは、データ収集の質です。
社内対応は機密性と柔軟性に優れ、自社の知見を活かせますが、リソースや品質管理の負担が大きくなりがちです。
一方、外注は専門チームによる高品質なデータ構築が可能で、大規模案件や短納期に強みがあります。
最適なのは、目的と状況に応じた使い分けです。
要件定義や検証を社内で行い、収集やアノテーションを外注する“ハイブリッド型”なら、
スピード・品質・リスクのバランスを取りながら効率的に進められます。
信頼できるパートナーと協働し、データを継続的に育てる体制を整えることが、AI開発成功への近道です。

